NB: This was a paper I wrote for my library school course, LIS 647 Visual Resources on May 5, 2014. I have not made any revisions or updates since that time.
Since the beginning of the twentieth century, our culture has become saturated with images, from advertisements to television to movies. With the proliferation of social media and cheap camera phones, that saturation has become all but complete. Images and photographs are hugely popular on social media. One of the most popular platforms, Instagram, revolves entirely around photographs created and shared by users. Instagram is a vibrant, information-rich record of contemporary history. It is used around the world by average people to celebrities to cultural institutions and captures anything from scenes of everyday life to world-changing events. It would not be outrageous to say that Instagram photos and other social media content will some day become part of the collections at archives and visual resource centers: the images created and shared on social media have been and will be vitally important to researchers, especially those interested in visual culture. But archiving an Instagram photo or other social media image is not like archiving other types of digital photography. Social media carries its own format and content idiosyncrasies, demanding a different kind of interaction by the archivist.
When the word “selfie” is chosen as the word of the year by Oxford Dictionaries, even the most conservative visual resource center must admit that the images of social media have a real, lasting place in visual culture[1]. Describing the discipline of visual culture, Beller writes, “What is visible, how it appears, and how it affects nearly every other aspect of social life is suddenly of paramount concern”[2]. This concept is exemplified in highly individualized, highly pervasive and image-heavy social media. For the visual resources community, this means their work has become more expanded, more difficult, and more important. An image shared on Instagram requires different archival considerations than a physical photograph or even a typical digital photograph, both technically and conceptually. As Gledhill observes (referring to digital content in general), “Building both the infrastructural capacity and methodological criteria for preserving this material represents a colossal paradigm shift for collecting institutions, whose identity has hitherto been constructed around materiality”[3]. Compared to analog formats, social media formats are somewhat unstable and often proprietary, making them highly liable for loss but also difficult to ingest into an archive. Social media platforms are constantly in flux, from the layout of websites, to the features offered or types of media supported, to the terms of service agreements users sign to continue using them. New social media platforms explode overnight and others disappear just as suddenly. This requires an enormous effort on the part of institutions to keep track of changes and adjust their archival practices if required. Some institutions may think that keeping up with trends across multiple social media platforms is too time-consuming and produces little to show for it, even if they maintain social media accounts themselves. However, it behooves collecting institutions to familiarize themselves with the way users engage with social media, not only for preserving any social media content the institution produces but also to prepare themselves to accept the future archival content from donors.
The content collected by archives and visual resource centers in the future will likely come from a variety of social media platforms, each with its own quality issues, metadata and file format standards[4]. It may not even come from the same user, but from many different users across the different groups of social media sites. Many archives are facing these problems now, such as the institutions trying to collect the social media ephemera of the Occupy movements. Part of the challenge is convincing content creators–many of whom may not even be aware of the concept of metadata–how to save important metadata and optimize their content for archival submission. The Activist Archivists, a group of New York archivists who charged themselves with archiving the Occupy Wall Street protest, encouraged protesters to distribute content under the Creative Common license so it could be archived without the standard, exclusive donor agreements. They also created short informational videos and postcards with tips on why archiving the movement was important and how protesters could make sure their content was in the best shape to be archived[5]. These informational items were short, easy to understand, and encouraged creators to collect as much information about the context of their content. They also advised not to upload to sites that would remove metadata: many commonly used services, such as YouTube or Vimeo, strip metadata when content is uploaded onto their sites[6]. Archives and visual resource centers may want to consider creating platform-specific creation/archival guides like the Activist Archivists’ for users who want to donate their social media content or for staff members who manage social media accounts for their institutions. Familiarizing themselves with the quirks of popular social media platforms will only better prepare them to archive this type of content in the near future.
Archiving social media is not without controversy. Users tend to feel strongly about their privacy, and feel that social media accounts–even if they are publicly available on the Internet–are personally “owned” by them and therefore private. This is particularly true for photos, which are often highly personal. In a survey about institutional practices for archiving social media, respondents tended to perceive photos as more personal than other types of social media and expressed concern about the potential loss of privacy and contextualization if those photos were archived by an institution[7]. Large scale archiving of social media sites may not be well received by users, who may feel that their privacy is being eroded. The safest course of action for institutions would be to focus on archiving their own social media accounts and/or social media content that has been donated. But even limiting an archive just to one’s own social media accounts will still involve the capture of personal information from outside users, for example, a user who comments on an Instagram photo. Therefore, institutions need to define their archiving boundaries clearly to put content creators and users at ease: the purpose of the archive, the type of access available, creator attribution, and use of archive material must be explicitly stated by the institution[8]. For example, the Smithsonian has made the decision not to archive the profiles of users who like or follow their social media accounts. However, they do capture comments and any account information linked to those[9]. Ultimately, the institution must be sensitive to the types of personal information present on different social media sites and individually determine whether or not it could breach a user’s privacy to archive it.
Despite the difficulties, there is much an institution can gain by archiving social media. Social media items, like any the content on the web, has no guarantee of permanence: just because something is online, does not mean it will last forever or be preserved. Based on research conducted by SalahEldeen and Nelson on embedded resources in tweets, 11% of web resources shared via social media disappear after a year, and then continue to disappear at a rate of .02% per day[10]. Within an institution, there may be unique content that is only found on social media accounts. This content has a high risk of being lost if the social media service goes out of business or suffers a catastrophic data failure. Cultural institutions should make sure that their content is preserved by taking action themselves, rather than hoping the social media company will handle it. Furthermore, social media may fall under certain recordkeeping requirements. Government agencies have a legal requirement to archive their social media; the National Archives and Records Administration (NARA) observed that “Content on social media is likely a federal record”[11]. Preserving social media also represents an opportunity to archive the images of marginalized or controversial groups, for example the Occupy movement[12]. The Occupy movement used social media heavily, using photos and video to document their protests and abuses at the hands of law enforcement. The images from Occupy are an important document of the early 21st century. Including them in an archive or visual resource collection would not be unusual, but figuring out the best way to add these images to an archival collection requires a little creative thinking. Archiving social media is exciting challenge, demanding careful thought and unique problem-solving from the part of the archive or visual resource center.
Since social media archiving is a relatively new practice, there is no one standard way to carry it out. Archival methods for social media are mostly homegrown and take a variety of forms. Identifying significant items among what can only be described as a deluge of material poses a huge challenge for archivists. When determining whether or not an item on social media should be archived, certain questions should guide the assessment process, such as, Is this content unique to the social media platform or is it available elsewhere? Does it convey important information? Could it constitute an official business record?[13]. Rate of capture is also an important consideration in the fast-moving world of social media, but figuring out how to capture it can be an even bigger challenge. Many social media services do not allow a user to export his or her data. While Twitter and Facebook both allow users to download an archive of their entire history and content, Instagram does not even allow users to download individual images except by right-clicking “Save As.” This makes it highly labor intensive to save images, since any metadata must be added manually. Some institutions take screenshots of different social media pages, others simply copy and paste content into word processing documents[14]. The Smithsonian Institution maintained nearly 80 Facebook pages in 2011, so the Smithsonian Institution Archives made the decision to archive a “representative sampling…to document how the Smithsonian used new technology in the early 21st century” besides archiving unique content[15]. In their case, they opted to capture the Facebook pages in PDF/A format. The PDFs must be completely self-contained, without audio or video. However, this process is time-consuming as the capture and cataloging cannot be automated: each page was manually opened and printed to PDF/A. By 2012, the Smithsonian had over five hundred social media accounts across various platforms, including Facebook, Twitter, YouTube, Flickr and blogs. Each of these focused on a different audience and contained different, specialized content[16]. Rather than archiving each of these accounts in their entirety, which would be too time-consuming and ultimately duplicative, the Smithsonian developed a special appraisal process for their social media accounts. Each account is reviewed individually to determine how much original, important content it contains. If the amount of unique content is great enough, the entire account is captured. Otherwise, only a sample of the account is captured to demonstrate how it was used[17]. Sometimes the content is crawled, other times it is exported into a spreadsheet or XML document. The Smithsonian’s approach represents a relatively straightforward, manual procedure for archiving that evolves as their social media needs grow and change. This homegrown approach may be the most useful and flexible for most institutions, since at present there are limited archival tools designed to archive social media. There are some third-party archival services available specifically for social media, and some of these are platform-specific. Most of the archival tools for social media are geared towards a lay audience, i.e. users trying to archive their personal collections, rather than an archive or library working off a preservation standard. After selection criteria and capturing methods have been determined, two core archival tasks need to be considered: how the items are captured from the web and how they are catalogued so they are made accessible.
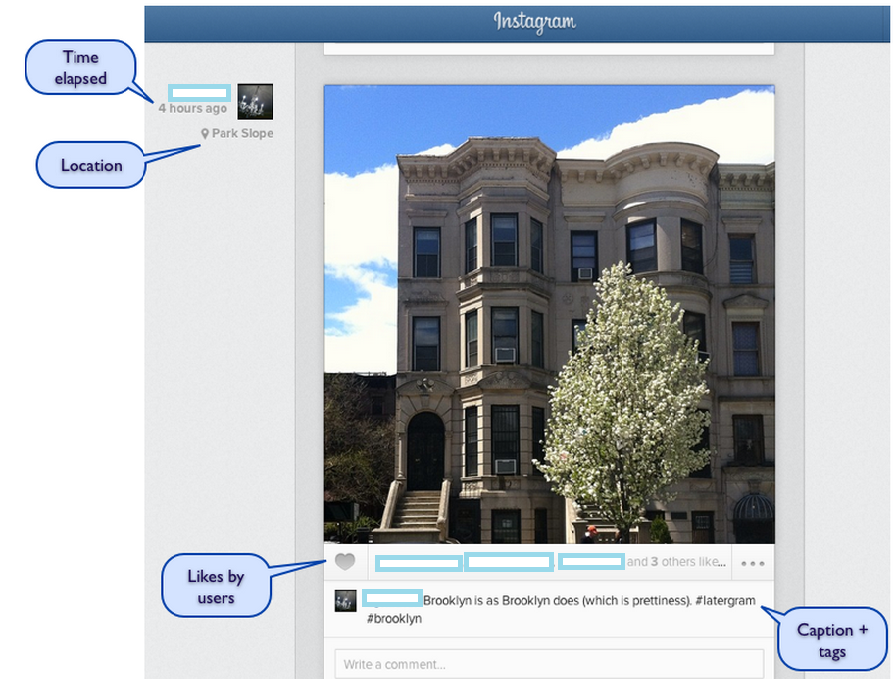
Figure 1. A typical Instagram post contains many layers of information.
Image-heavy social media content may be adequately cataloged by existing content standards and metadata schemas such as VRA Core and CCO. However, it may be some time before the standards’ committees formally develop and publish how social media images should be cataloged. Until then, visual resource centers and archives will need to adapt their current cataloging practices to fit social media as best they can. The nature of social media makes it difficult to fit neatly into existing cataloging standards. For instance, could a user’s entire social media account be considered a “collection” under VRA Core, or should a collection be more narrowly defined, such as every post with a specific tag (e.g. #CapeCod, #wedding)? The cataloger must also understand the “culture” of a social media account to best capture important information. Consider hashtags: on Instagram, users add hashtags as both a folksonomy classification and also a way to comment on their post (like an aside in a theatrical production). Understanding how a user utilizes hashtags in a particular post will affect how it is cataloged. A cataloger may look at one hashtag (e.g. #gradschool) to guide how she completes the Subject field, while recognizing that another hashtag (e.g. #wishIcouldlivehere) is really a part of the caption and not a classification tag from the user. Further adding to the challenge is the sheer amount of information that social media posts and images consist of. A single Instagram photo contains multiple layers of information: there is the photo and its subject, the caption, the tags, the geographic location, the “likes” from other Instagram users, and comments. Deciding how VRA/CCO will be used to catalog all these pieces of information requires mindful consideration and a clear understanding of how the culture of Instagram operates. For example, take the Location field for CCO. A user may add her geographic location to an Instagram photo, but it may not be something found in the Getty Thesaurus of Geographic Names: sometimes a user marks her location as “Home” while still capturing GIS data. How should these two separate locations–the meaningful one marked by the user and the actual physical location–be cataloged? Even a field like “Title” poses a conundrum. Is the caption of an Instagram photo a title? If not, under what field should the caption be recorded? There are several ways an Instagram photo or other social media post can fit into VRA/CCO depending upon the needs of the archive and the nature of the social media collection. Although each social media platform has its own particular quirks and user practices, a cataloging practice developed for one platform may easily apply to another. An Instagram post is not all that dissimilar from a Twitter post with a photo in terms of information content. Adapting VRA/CCO for social media will allow archives and visual resource centers to accept social media collections and make them accessible to users, placing them at the cutting edge of web archiving and establishing a good procedure for future digital submissions. In time, there may even be archival tools developed specifically for archiving Instagram and other social media sites. Currently, the field is rather slim.
Instagram itself does not offer any native archiving feature. Users are not able to download images at all, let alone with any sort of contextual information or metadata. This makes it a challenging service for librarians to archive. For digital image files, technical metadata is not sufficient; descriptive metadata should also be directly embedded into an image file to create a completely contained object[18]. And there is a lot of metadata that can be added. On Instagram, users may add geographic locations, captions, tag other users, but it is not clear what is automatically recorded by Instagram if users do not manually add any descriptive information. Limited metadata is displayed in the Instagram post, and can be edited by the user. An Instagram post displays the user who uploaded the image (although this may not be the user who took the photo), an optional caption (which may include manually added hashtags), an optional geographic location, and optional tagging of other Instagram users. The date is not displayed, but rather a relative time of when the post was uploaded (e.g. “5d” for “5 days ago”). But none of these information is transferred when images are downloaded from Instagram. According to tests run by the Embedded Metadata Manifesto initiative, Instagram strips embedded metadata if image files are saved from a web browser and does not allow images to be downloaded directly through its user interface[19]. Ideally, a social media archiving service would be able to pull all of these information from an Instagram post, but not every service is able to properly capture metadata or even the image itself. Certain social media curation services, such as Storify, merely create the appearance of preservation without actually archiving resources: if a resource is removed from the original source, it also disappears from the curated collection[20]. The options for archiving one’s Instagram account are relatively limited. Two third-party options are Recygram and Instaport. While these programs were not created with an archival audience in mind, they were tested to see if they could be of any use to an archive or visual resource center, or even if they could be recommended to potential donors to compile their Instagram posts for archival submission. The review was guided by the following questions: How much can be downloaded at once? Can the user select specific items to download? What format is it downloaded in? What is the quality? What information is captured? How easily can this be turned into an submission ready for archiving? The answers to these questions were not promising. Both of these are geared toward a casual Instragram user and unfortunately would have very limited applications in an archival setting.
Recygram (http://www.recygram.com/) is an app available on iPhone only. It requires you to log in to your Instagram account from the app, which gives Recygram authorization to access basic account information, and also allows it to comment or like photos you post. The application can send Instagram photos directly to Flickr or Tumblr, save to the iPhone’s camera roll, or save to a zip file. The user can select all photos or designate specific photos save. The zip file may be sent to email, Google Drive, Dropbox or other sharing apps such as Evernote. The zip file downloads Instagram photos as 640 × 640 jpegs. An image file contain no embedded metadata, and the file name is a completely random string of letters and numbers. To upload an Instagram photo to Flickr requires giving Recygram access to the Flickr account, to upload/edit/replace photos, and to interact with other members’ photos (e.g. comment, favorite). This seems like giving Recygram a little too much control over the Flickr account, but it is unclear what giving Recygram the ability to comment on other users’ photos truly entails. Several times, the application unexpectedly quit when trying to load additional Instagram photos to select. Again, when uploading to Flickr, Recygram included no metadata and gave the photo a random string of numbers/letters as a file name. While the application is very easy to use, the fact that it exports no metadata and can only be used on iPhones (not even iPads) makes it practically useless for an archival institution. A few reviews of the product make the case that Recygram is very learnable and makes it simple to quickly move your entire Instagram archive to other social media services such as Flickr or Tumblr[21]. While this could be a useful feature, because Recygram captures no metadata and does not use descriptive file names, it would require a lot of additional work by the archivist to create even a minimum amount of metadata to add the images to Flickr or Tumblr, let alone preparing it for addition to an archive. Another third-party service for archiving Instagram is Instaport, which had some greater flexibility but ultimately had the same problems as Recygram.
Instaport (http://http://instaport.me/) is a web-based service, so unlike Recygram it can be accessed from any computer. By signing in with Instagram, you authorize the service to access basic account information. Instaport allows you to export all photos or select photos based on specific criteria, such as within a certain timeframe (e.g. the last 10 photos taken), photos taken between specific dates, photos which you liked, or photos tagged with a specific hashtag. The hashtag option cannot be limited by time and there is a max of 500 photos that can be downloaded with this option, so if the same hashtag is used constantly this could produce duplicated captures or miss the 501+ photo. It takes a few minutes for the site to produce a zip file which can be directly downloaded to your computer. The download date is included as part of the zip file’s filename. As with Recygram, the photos are downloaded as 640 × 640 jpegs. However, unlike Recygram, the filename for each photo includes a unique identifier and the date the photo was uploaded to Instagram. This is a more useful file naming system than Recygram’s and provides an easier way to track photos. However, no other identification information or metadata is downloaded. While Instaport is more useful than Recygram and allows for more specific types of file selection, it is still very limited for an archival institution’s needs. In both cases, the quality of photos is generally poor, but this seems to be a problem originating in Instagram. Panzarino observes that the service is a good way for a photographer to quickly create a backup of his or her Instagram photos[22]. However, like many social media archiving services, Instaport is better suited to individual users just trying to manage their own personal photos or move a large amount of photos from one service to another. An individual user may be frustrated that Instaport does not capture any photo details, but overall he or she is less likely to be concerned with its lack of metadata than an archivist. Until more robust archiving tools are available, many institutions will have to be creative and flexible in order to archive social media.
Social media presents a unique challenge for archives and visual resource centers. While some archival tools have been developed, we are still a long way from having a single, efficient tool that could capture and prepare social media content for an archive. Until then, institutions will need to develop individual solutions that best fit their own needs, whether it is just archiving their own social media presence or capturing content from users across the web. Similarly, developing cataloging procedures that adequately serve social media items will require careful thought by catalogers and metadata specialists. Archiving social media requires many new archival practices and procedures, demanding a substantial effort on the part of archives and visual resource centers. Social media is a key record of our present history and will become an integral part of archives in the future. While the task of archiving social media appears burdensome, the investment of time and effort to develop best practices will be vital to the archives and users of the future.
Footnotes
[1] Brumfield, B. (2013, November 20). Selfie name word of the year for 2013. CNN. Retrieved from http://www.cnn.com/2013/11/19/living/selfie-word-of-the-year/
[2] Beller, J. (2005). Visual culture. In M. C. Horowitz (Ed.), New Dictionary of the History of Ideas (Vol. 6, pp. 2423-2429). Detroit: Charles Scribner’s Sons. Retrieved from http://go.galegroup.com/ps/i.do?id=GALE%7CCX3424300803&v=2.1&u=nypl&it=r&p=GVRL&sw=w
[3] Gledhill, J. (2012). Collecting Occupy London: Public Collecting institutions and social protest movements in the 21st century. Social Movement Studies, 11(3/4), 342-348.
[4] Besser, H. (2013). Archiving aggregates of individually created digital content: Lessons from archiving the Occupy Movement. Preservation, Digital Technology & Culture, 42(1), 31-37. doi: 10.1515/pdtc-2013-0005
[5] Ibid.
[6] Ibid.
[7] Marshall, C.C., & Shipman, F.M. (2012). On the institutional archiving of social media. In Proceedings of the 12th ACM/IEEE-CS Joint conference on Digital Libraries (pp. 1-10). New York, NY: Association for Computing Machinery.
[8] Ibid.
[9] Wright, J. (2012, June 13). To preserve or not to preserve: Social media [Web log post]. Smithsonian Institution Archives. Retrieved from http://siarchives.si.edu/blog/preserve-or-not-preserve-social-media
[10] SalahEldeen, H. M. & Nelson, M. L. (2012). Losing my revolution: how many resources shared on social media have been lost? In P. Zaphiris, G. Buchanan, E. Rasmussen, & F. Loizides (Eds.), Proceedings of the Second International Conference on Theory and Practice of Digital Libraries, TPDL 2012 (p. 125–137). New York, NY: Springer.
[11] Quoted in Moore, J. (2013, November 25). Social media: The next generation of archiving. FCW. Retrieved from http://fcw.com/articles/2013/11/25/exectech-social-media-archiving.aspx
[12] Gledhill, 2012.
[13] Moore, 2013.
[14] Ibid.
[15] Fuhrig , L.S. (2011, May 31). The Smithsonian: Using and archiving Facebook [Web log post]. Smithsonian Institution Archives. Retrieved from http://siarchives.si.edu/blog/smithsonian-using-and-archiving-facebook
[16] Wright, 2012.
[17] Ibid.
[18] Reser, G., & Bauman, J. (2012). The past, present, and future of embedded metadata for the long-term maintenance of and access to digital image files. International Journal of Digital Library Systems, 3(1), 53–64. doi:10.4018/jdls.2012010104
[19] Embedded Metadata Manifesto. (2013). Social media sites: Photo metadata test results. Embedded Metadata Manifesto. Retrieved from http://www.embeddedmetadata.org/social-media-test-results.php
[20] SalahEldeen & Nelson, 2012.
[21] LeFebvre, R. (2013, March 1). Archive, batch send, and download your Instagram photos with Recygram [Web log post]. Cult of Mac. Retrieved from http://www.cultofmac.com/218098/archive-batch-send-and-download-your-instagram-photos-with-recygram-ios-tips/
[22] Panzarino, M. (2011, July 1). Instaport: Download your entire Instagram archive for backup or upload. The Next Web. Retrieved from http://thenextweb.com/apps/2011/07/01/instaport-download-your-entire-instagram-archive-for-backup-or-upload/
